Breaking Things Again: Status Page Edition
January 5, 2022

Breaking what should not be broke
You know when you have a simply lovely day? Like you’re walking through the city and you think “yeah, I’m happy”? That was me about six or so hours before getting home and figuring I would write this. It probably sounds like this issue absolutely ruined my day, it really didn’t. It was more a moment of an over exaggerated exhale of air and sitting down to see how quickly I could resolve this.
This centres around my Uptime Kuma instance, which I have running on a T4G.Nano on AWS. I got some pings into a Discord channel from Kuma that said two of my self hosted applications were down due to a timeout after 49500 milliseconds, which is some what long. I loaded the two apps and they responded straight away, so my first thought was network related perhaps, but then all the monitors would be failing most likely. So, I checked the server, the containers for those apps were both alive and well with no apparent restarts. That then lead me to Uptime Kuma itself and I couldn’t load the front end. I could also not SSH to the instance, which lead me down the age old classic of a reboot.
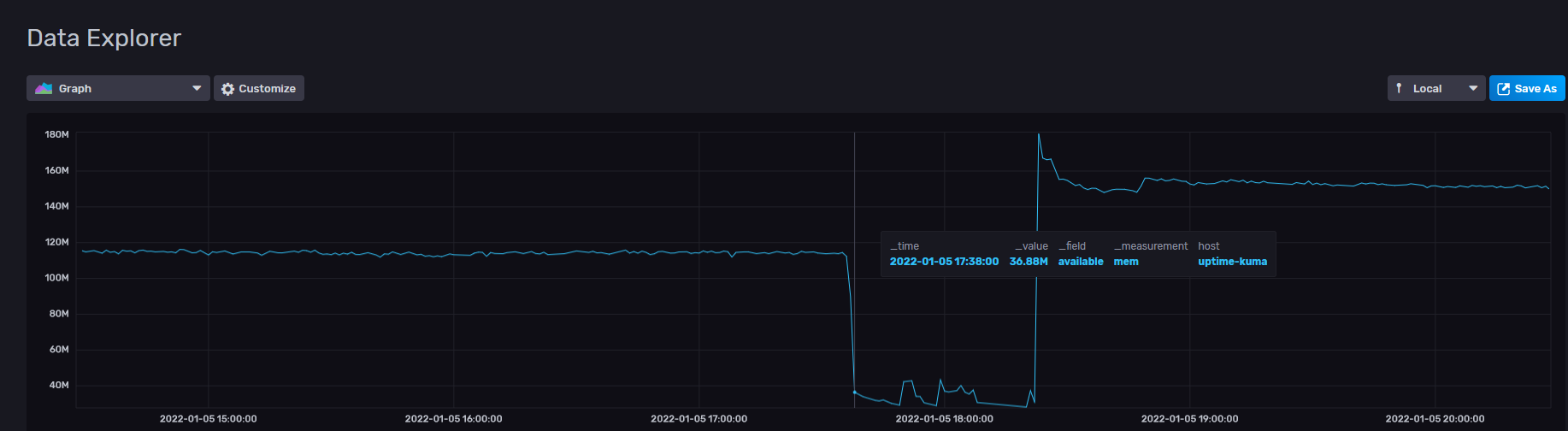
Sure enough, reboot solved things and we came back up. Wonderfully enough and a spoiler for future content, I’ve been working on implementing a Telegraf, InfluxDB and Grafana, or TIG stack as it’s known. So it was a perfect opportunity to try and see what was up. AWS metrics in the console never have RAM as an option and sure enough:
Screenshot of InfluxDB showing the memory trend over time for a virtual machine
{kind=link}
Something exhausted the memory on the instance is my guess. Looking at other metrics in AWS, I do see the host started reporting as unhealthy in the load balancer, but the health checks did not start failing till around 30 minutes after that fact. But it does line up with the apparent memory exhaustion.
Ultimately this is rather low on my priority list in terms of finding an actual root cause. Uptime Kuma has been great to me and for all I know, 512MB of RAM is not the recommendation for it. I would prefer to make it more available with another nano instance, but I don’t think it’s designed for that yet and it may even be out of scope for something that is kind of targeted towards hobbyist monitoring. But it does get some wheels turning in terms of automation ideas, would be cool if based on data from Influx, an action is performed like an instance reboot. Something to research anyway!
Thank you!
You could of consumed content on any website, but you went ahead and consumed my content, so I'm very grateful! If you liked this, then you might like this other piece of content I worked on.
My original status page implementationPhotographer
I've no real claim to fame when it comes to good photos, so it's why the header photo for this post was shot by Marc-Olivier Jodoin . You can find some more photos from them on Unsplash. Unsplash is a great place to source photos for your website, presentation and more! But it wouldn't be anything without the photographers who put in the work.
Find Them On UnsplashSupport what I do
I write for the love and passion I have for technology. Just reading and sharing my articles is more than enough. But if you want to offer more direct support, then you can support the running costs of my website by donating via Stripe. Only do so if you feel I have truly delivered value, but as I said, your readership is more than enough already. Thank you :)
Support My Work